Introduction to Unsupervised Machine Learning
Introduction to Unsupervised Learning
in the previous topic we learn about types of Machine Learning and Supervised learning. In Supervised learning we train model on label data. but there may be many cases where we do not have label on data, here comes Unsupervised learning techniques.
What is Unsupervised Learning
Unsupervised learning is a branch of machine learning where the algorithm is tasked with finding patterns or structure in input data without explicit guidance or labled outcomes. Unlike supervised learning, where the algorithm is trained on labled data to make predictions or classifications, unsupervised learning operates on unlabled data. This type of learning is particularly useful when dealing with data that lacks clear labels or when the objective is to uncover hidden patterns or relationships within the data.
Example: Suppose the unsupervised learning algorithm is given a dataset of big box of colourful toys, algorithm does not trained on the given dataset, that’s mean algorithm does not have any idea about the features of the datasets. So, unsupervised learning is like organizing your toys without anyone telling you how to do it. You use clever tricks to group them, simplify them, find the odd ones out, and figure out the rules they follow. And just like with toys, unsupervised learning helps computers organize and understand big piles of information all on their own!

Why use Unsupervised Learning?
below are the some reason to use unsupervised learning.
- Discover hidden patterns: Finds hidden patterns or structures in data.
- Handle unlabeled data: Works with data that doesn’t have labels.
- Preprocess data: Simplifies data and removes noise for better analysis.
- Detect anomalies: Identifies unusual or outlier data points.
- Segment customers: Groups similar customers for personalized recommendations.
- Explore data: Helps understand the structure and relationships within data.
- Generate new data: Creates new data samples similar to existing ones.
Working of Unsupervised Learning:
process of unsupervised learning can be found by below image:
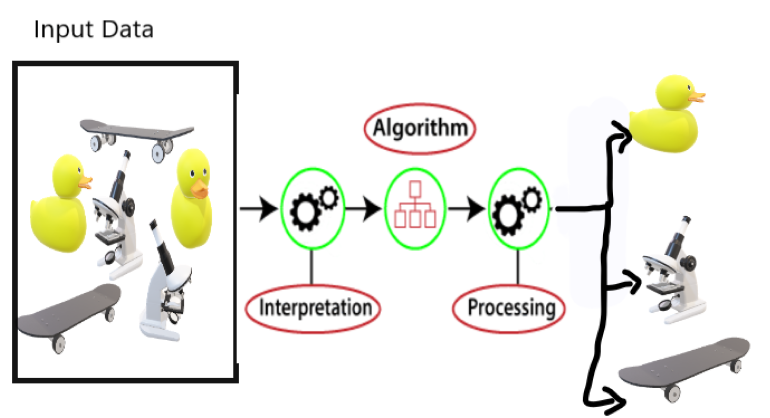
Here, we have taken an unlabeled data, that’s mean we does not know about anything about the data. now this data is given to the Machine Learning Algorithm in order to train. First it interpret the raw data to find the hidden pattern (like color, size, etc) from the data and then apply any suitable algorithm.
Types of Supervised Learning Algorithm:
Clustering:
Clustering is a technique in unsupervised learning where similar data points are grouped together into clusters, with the objective of discovering inherent structures or patterns within the data. The algorithm categorizes data points based on their similarities, aiming to minimize intra-cluster distance and maximize inter-cluster distance.
Association:
Association rule learning is a way of finding connections between things in a big collection of information. It figures out which items usually go together. For example, it might notice that people who buy bread often also buy butter or jam. This helps businesses make smarter decisions about what to sell and how to sell it. It’s like understanding that certain things usually come as a package deal when people shop. This method is often used in something called Market Basket Analysis.
Types of Unsupervised Learning Algorithms:
below are the few popular unsupervised algorithms:
- Anomaly detection
- PCA (Principle Component Analysis)
- K- means clustering
- Hierarchical Clustering
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Apriori algorithm
- Gaussian Mixture Models (GMMs)
Advantages and Disadvantages of Unsupervised Learning:
Advantages:
- No Need for Labeled Data:
- Unsupervised learning doesn’t require labeled data, so you can work with raw, unlabeled data easily.
- Discover Hidden Patterns:
- Unsupervised learning can find hidden patterns in data that might not be obvious to humans.
- Flexible and Versatile:
- It can handle a wide variety of data types and structures, making it useful in many different situations.
- Preprocessing Aid:
- Techniques like clustering and dimensionality reduction can help preprocess data for further analysis or visualization.
- Exploratory Insights:
- It’s great for exploring and understanding new datasets, helping you uncover interesting insights.
Disadvantages:
- No Ground Truth:
- Since there are no labeled outcomes, it’s harder to evaluate the performance of unsupervised learning algorithms.
- Subjective Interpretation:
- Results can be subjective and depend heavily on how the algorithm interprets the data’s similarities and differences.
- Difficulty in Validation:
- It can be challenging to validate the accuracy of clustering or association results without a clear benchmark.
- Computationally Expensive:
- Some unsupervised learning algorithms can be computationally expensive, especially with large datasets.
- Limited Task Scope:
- Unsupervised learning is not suitable for tasks that require precise predictions or classifications, as it doesn’t have explicit guidance from labeled data.

- How to Download Stock Data Using Interactive Brokers – 2024 - July 8, 2024
- Exploring the Best Python Libraries for Machine Learning – 2024 - April 20, 2024
- What is ElegantRL - April 11, 2024
5 Comments